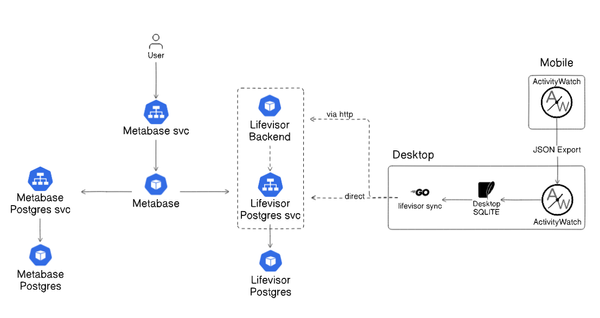
Going Mobile: Part 5


In this final post of the Going Mobile series, I'll go over some issues I have faced while deploying the system, and provide a summary of the solutions I chose to resolve them.
Networking (again):
svclb timing out:
Upon deploying the nodes in different locations I realised that while the k3s svclb (Service Load Balancer) pods were deployed to each node correctly, an HTTP GET request to the address of the nodes that didn't have a 'locally available' traefik pod running would eventually return a timeout. I wrote this down to an issue in cluster communications, so decided to set up cluster communications via the embedded k3s multicloud solution.
This resolved the problem of the svclb pods responding correctly via HTTP ('404 page not found' as default from traefik) but revealed another issue, latency between svclb and traefik.
Latency between svclb and Traefik:
Network latency between pods scheduled on nodes in a location where the default k3s traefik pod was not scheduled caused significant flapping for the HAProxy instance, this proved to make accurate health checks impossible from HAProxy in this current arrangement.
The solution for this was to use the svclb node pool functionality, creating a node pool for each location, and also scoping a new traefik pod deployment to provide location-scoped pods, Below is an example with 2 pools:
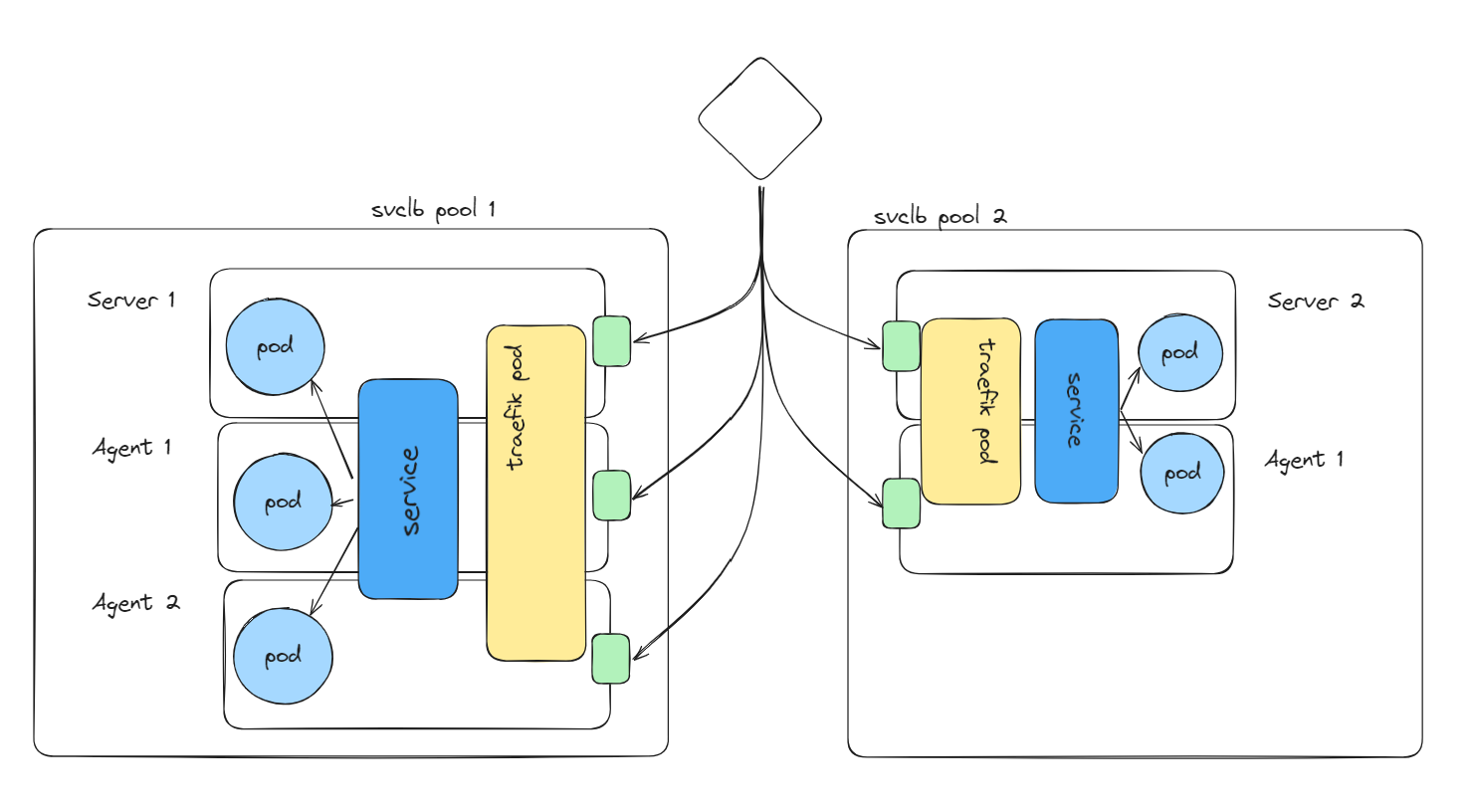
While this set up allowed svclb to finally reach the pods in the different pools appropriately, I have had to increase the HAProxy check times to accommodate the latency.
The above example has the following manifests:
Codeserver-values.yaml:
image:
repository: docker.io/codercom/code-server
pullPolicy: IfNotPresent
tag: 4.20.1@sha256:94e705de31ca2e6d0c28fec83f004c4159c037338c485ca0b60bba7e90bde8f9
securityContext:
container:
readOnlyRootFilesystem: false
allowPrivilegeEscalation: true
runAsNonRoot: false
runAsUser: 0
runAsGroup: 0
service:
main:
ports:
main:
port: 10063
protocol: http
targetPort: 8080
workload:
main:
enabled: true
type: DaemonSet
revisionHistoryLimit: 3
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 1
podSpec:
containers:
main:
probes:
liveness:
type: http
path: /
readiness:
type: http
path: /
startup:
type: http
path: /
env:
PROXY_DOMAIN: ""
args:
- --user-data-dir
- "/config/.vscode"
- --auth
- none
persistence:
config:
enabled: false
mountPath: /config
portal:
open:
enabled: truecodeserver-IngressRoute.yaml:
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: codeserver-ingressroute
namespace: default
spec:
entryPoints:
- web
routes:
- match: Host(`codeserver.example.com`)
kind: Rule
services:
- name: codeserver-code-server
port: 10063haproxy.cfg:
# Backend for Codeserver
backend codeserver_backend
mode http
balance roundrobin
option httpchk HEAD / HTTP/1.1\r\nHost:codeserver.example.com
http-request set-header Host %[req.hdr(Host)]
server agent1 agent1:80
server agent2 agent2:80 backup
server agent3 agent3:80 backup
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
option forwardforWhile, not necessary, running replicas on each svclb node pool appears to be ideal for high availability and reliability.
HAProxy stats:
A feature of HAProxy which I have found instrumental in terms of observability of HAProxy's metrics aswell as well as the overall health of the load balancing set up is the HAProxy stats page, it can be enabled with the following example config:
frontend stats
mode http
bind *:8404
stats enable
stats uri /stats
stats refresh 10s
stats admin if LOCALHOSTAn example of the above codeserver_backend taken from my HAProxy stats page is as follows:

The above showing that the stats page provides details on:
- Backend server uptime
- Last Health Check status and latency
- Total service downtime
- Queues, Session Rates, Time since last session.
Essentially everything you would need from your load balancer at a glance.
Note: If you wish to incorporate HAProxy metrics into your Prometheus based monitoring solution, it is also possible to expose a Prometheus metrics endpoint: See here
Final wrap up:
This project began as a modest concept and has since expanded remarkably, significantly enhancing my understanding of various aspects involved in developing highly available distributed systems.
A major 'aha' moment: A major issue for me over the entire duration of the project was how I could manage the scoping of applications and making them available via their service (we can deploy them, but they wont all be local without specifically deploying a daemonset), however as described in this post, a major 'aha' moment for me was the functionality and combination of 1. Functionality of svclb pools and 2. Location scoped traefik pods. Once I understood that topology, all the other solutions fell into place.
Next steps: The next steps for this project will be to continue to incorporate ideas and tools which I learn about and help to improve the underlying reliability of the infrastructure, one idea is to build the same system but using k0s in place of k3s. Something which I am hopeful for in the future to incorporate is the Traefik failover service for the Kubernetes provider, see the GitHub issue: here.
Another interesting idea to try out, could be to use the HAProxy Kubernetes Ingress Controller.
Resource list:
- k3s documentation: https://docs.k3s.io/
- Traefik documentation: https://doc.traefik.io/traefik/
- HAProxy blog: https://www.haproxy.com/blog
- Chaos-Mesh docs: https://chaos-mesh.org/docs/
- Tailscale docs: https://tailscale.com/kb
- Headscale documenation: https://headscale.net/
- Truecharts documentation: https://truecharts.org/manual/intro
Thank you for joining me through this journey in the 'Going Mobile' series. I hope you found these insights into distributed Kubernetes clusters both enlightening and practical. My goal of this blog is to delve deep into the realms of Self-hosting, DevOps, and Reliability Engineering, uncovering the latest trends, sharing compelling stories, and offering hands-on advice.
Finally, If you're on the brink of starting your own multi-location cluster or have been tinkering with k3s in your lab, share your story. What challenges are you facing? What successes have you celebrated? Your experiences improve the community and pave the way for growth.
Feel free to reach out to me on LinkedIn or GitHub
Explore the series:
This post is part of the 'Going Mobile' series. Explore the series further:
- Going Mobile: Part 1 - Introduction to the series
- Going Mobile: Part 2 - The design.
- Going Mobile: Part 3 - Understanding a change in the scope.
- Going Mobile: Part 4 - Going further into Networking, Monitoring and Chaos engineering
- You are here: Going Mobile: Part 5 - Covering some troubleshooting, wrapping it up, and the future.