Automating PostgreSQL Clusters: A Guide to Deployment with ArgoCD and CloudNativePG


Use case:
To be able to deploy and manage PostgreSQL clusters with GitOps and to provide an auditable and easily understandable system for developers to manage their own Postgres clusters from the same git repo.
Brief description of the tech involved:
GitOps with ArgoCD:
GitOps is a software and deployment approach where the definition and lifecycle for the entire infrastructure and applications are managed through Git repositories, this makes the repo a single source of truth for our infrastructure, and also allows us to use CI/CD practices with our infrastructure. ArgoCD is a GitOps continuous delivery tool for Kubernetes, ArgoCD will listen to our repo and deploy the changes for us to reach our desired state.
Kubernetes Operators:
Operators are extensions to Kubernetes that creates custom resource definitions (CRDs) which are used to manage applications and components of those applications, Operators follow the Kubernetes control loop principle, where a controller will check the current state of its related resources vs the desired state and communicates with the Kube-API server to make those changes. For more detail see: Operator pattern and Controllers
CloudNativePG:
CloudNativePG is a Kubernetes operator for covering the lifecycle of PostgreSQL clusters, it provides many features for deploying and managing high availability database clusters. CloudNativePG is an "Autopilot" capability Operator, which is the highest level of an operator, allowing for:
- Basic installs
- Seamless Upgrading
- Full Lifecycle
- Deep insights with metrics
- Horizontal and Vertical scaling + auto-config tuning
Read more about the CloudNativePG operator at OperatorHub
For our use case, CloudNativePG provides the controller and CRDs for managing our PostgreSQL clusters.
How the system works:
The CloudNativePG operator will create the CRDs needed for our clusters in our Kubernetes cluster, the main one being Cluster this CRD defines everything for our cluster, an example of a basic cluster would be:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 3
storage:
size: 1Gi
The above manifest defines an Postgres cluster, with 3 replicas, and a storage size of 1Gi.
However, if we are going to deploy this in a GitOps manner, we will need to build the yaml manifests in our directory which ArgoCD will be monitoring for changes. An example of this will be the pg-clusters/cluster1.yaml manifest, which for example would look like:
pg-clusters/cluster1.yaml:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: generator-cluster1
namespace: default
spec:
description: "Generated Cluster 1"
imageName: ghcr.io/cloudnative-pg/postgresql:15.1
instances: 1
startDelay: 10
stopDelay: 10
primaryUpdateStrategy: unsupervised
bootstrap:
initdb:
database: postgres
owner: app
secret:
name: cluster-example-app-user
superuserSecret:
name: cluster-example-superuser
storage:
size: "1Gi"
monitoring:
enablePodMonitor: true
We will now need to create a new app in ArgoCD, to do this and to make sure it builds the resources from the correct directory (in our example this will need to be the pg-clusters directory), we will provide the following Application manifest:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: pg-clusters
spec:
destination:
name: ''
namespace: default
server: 'https://kubernetes.default.svc'
source:
path: pg-clusters
repoURL: 'https://github.com/azaurus1/gitops-pgclusters'
targetRevision: HEAD
sources: []
project: default
Once this Application is deployed into ArgoCD, a sync will begin to reconcile the desired and current states and begin to deploy our Cluster as defined in the earlier manifest.
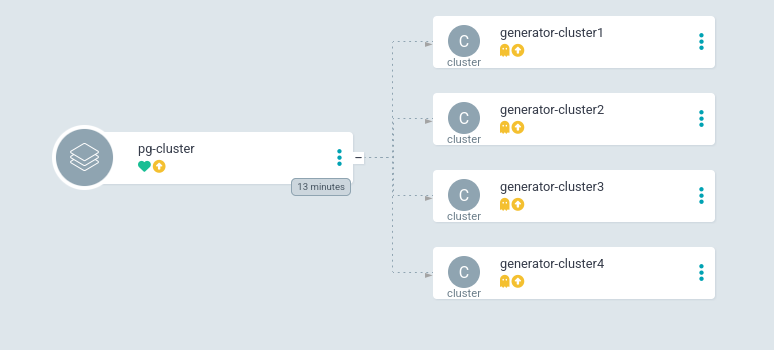
The above is an example of the deployed pg-cluster application in the unsynced state, we can build our cluster by syncing the cluster resource, an example of syncing the generator-cluster1 cluster would look like below:
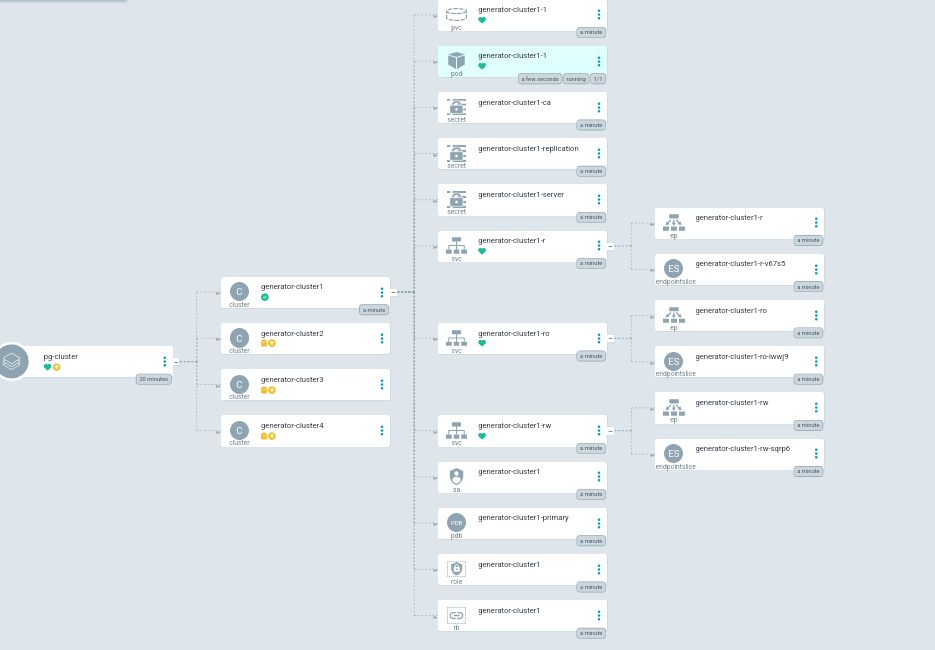
As we can see, we now have a nice view of all the resources required for our PostgreSQL Cluster that have been provisioned in our cluster, and they match our manifest specifications, including the 1 Instance, 1Gi PersistentVolumeClaim. On top of this, the clusters are all in the same Application and can be easily managed from one view.
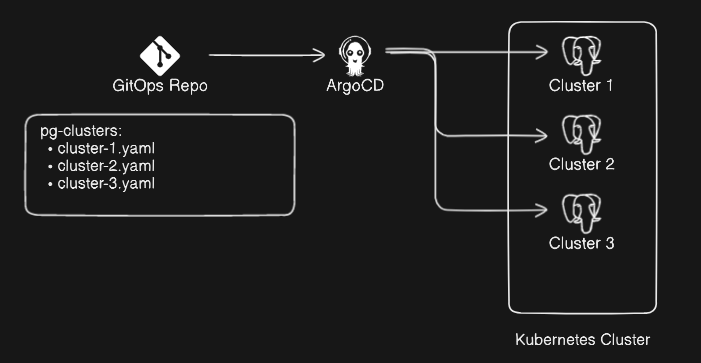
Graphical Representation:
Sources:
- A very useful source I found for managing Operators in ArgoCD was here: https://piotrminkowski.com/2023/05/05/manage-kubernetes-operators-with-argocd/
- My example repo: https://github.com/azaurus1/gitops-pgclusters